Sample Data Match Report
Connects to Live Data and Runs with a "Single Command" - see Generative AI Utilization in Action

Example - Connect and run a Company Name Match Report with a "single command" (HTTP query with parameters - 100% in the Cloud - nothing to install).
Try it now from the address bar (or click on the link). An API key is not needed for the sample CSV file stored in the Cloud (in AWS S3 in this example). The data will be analyzed in the Cloud and clustered matches and hashed similarity keys will be shown as output:
You can run this from any command-line using cURL, in which case remove the "html=true" parameter. The command is the same with SQL-based Cloud database platforms - only a database connection string is needed to access the data source, as there is nothing to install. For more documentation on the above command, including using cURL to run from the command line, how to set parameters, and to see how to incorporate data cleansing, matching, and data enrichment as part of workflow, including scheduled runs, ongoing processing, or as part of a data pipeline, see the Data Matching Workflow Guide.
Want to try it with your own data? Register for a free trial to get your API license key
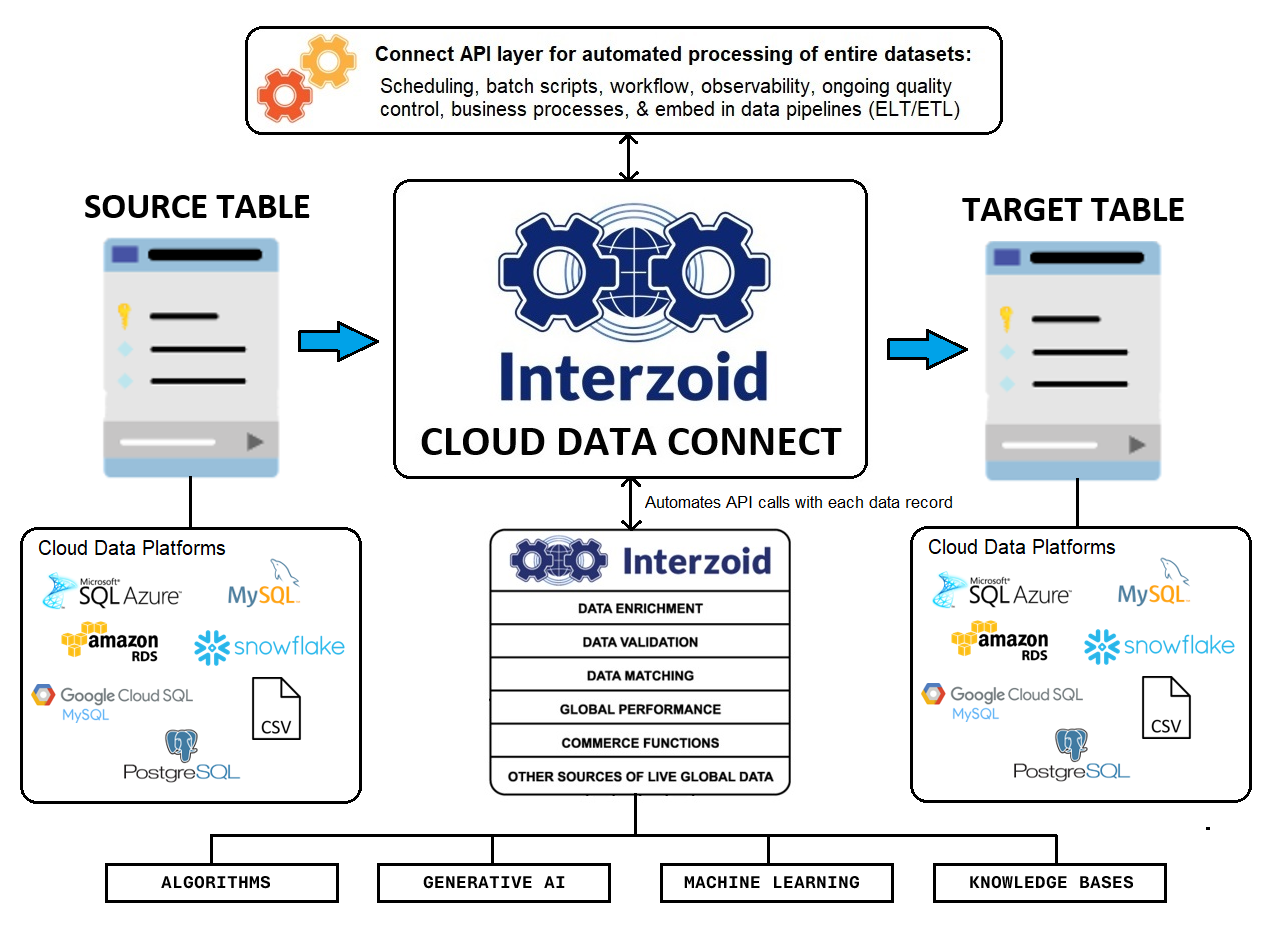
Would you like to run data functions against entire datasets like this interactively from the browser? Check out our quick and easy Data Matching Tutorial using our no-code Cloud Data Connect product to see an example of how data from a Cloud source can be analyzed, processed, and enriched interactively from the browser, utilizing our matching APIs behind the scenes.
No usage is charged for the first 1000 records of a match report (to identify duplicate/redundant/inconsistent data) for database tables or files.