Launch on AWS Marketplace
Deploy Interzoid's AI-Powered Data Matching on your AWS EC2 instance today!
Get StartedAnalyze, process, and generate data matching and anomaly reports for databases and datasets on EC2. Access local, network, or Cloud databases and files directly from the instance.
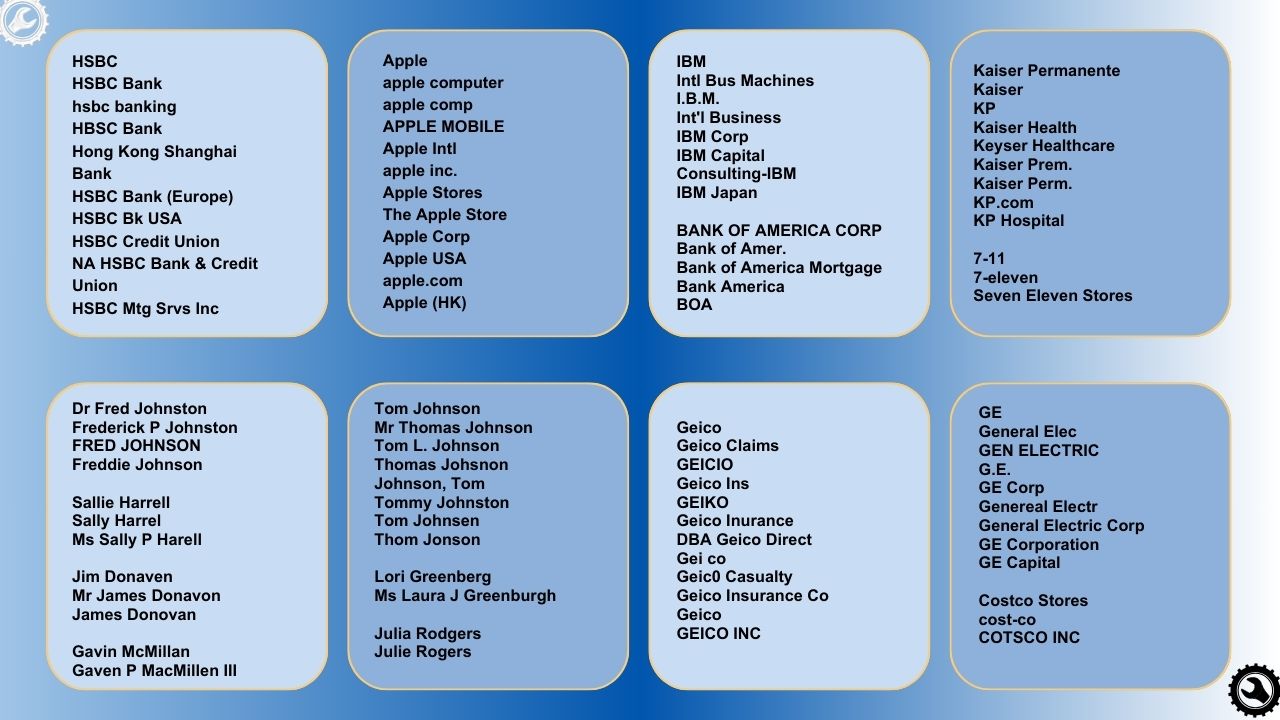
Identify and resolve data quality issues quickly and easily, regardless of how and where the data resides. Get up and running in minutes and achieve better quality and usability immediately.
Deploy Interzoid's AI-powered matching system to an instance of AWS EC2, enabling full-control, unlimited access, and maximum flexibility - all within your own Virtual Private Cloud (VPC).
Our native connectors enable the processing of entire data tables and datasets within the most popular databases and file types. Data can reside locally, within your VPC, or across the Cloud.
Deploy Interzoid's AI-Powered Data Matching on your AWS EC2 instance today!
Get StartedThere are two components to the platform once deployed:
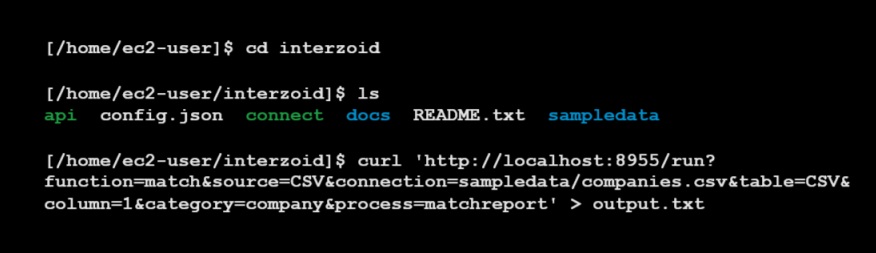
* For SQL databases use the appropriate connection string (see docs).
We use Generative AI to dramatically enhance our data matching and "inconsistently represented data" identification capabilities. We've built a specialized language model into the product, transparent to the user, that enables these advanced capabilities. It is used by our matching algorithms during the analysis and processing of data.
You only need an existing Amazon AWS account. Within your account, from the AWS Marketplace you simply launch the Machine Image to an EC2 instance, and you're off and running.
Yes. There are no geographic restrictions.
No. It is billed inexpensively by the hour, so you can use it for only one hour to run data quality anomaly and match reports against datasets if desired, and/or to test drive it with existing data or datasets. Usage cost only occurs while the deployed EC2 instance is running.
The hours of usage are simply part of your normal, monthly AWS bill. There is no separate billing.
You can quickly connect to SQL-based database tables using our built-in native drivers to begin analysis and matching, including AWS RDS, AWS Aurora, AWS Redshift, Snowflake, Databricks, Azure SQL, Google SQL, Postgres, MySQL, and others. You can also analyze and process data from flat files, including CSVs, TSVs, Parquet, and Microsoft Excel.
Yes. While you can choose to access and process data entirely behind your own firewalls, you can also connect to databases and files that are either out in the Cloud, on-premise, or on your own workstation or laptop for analysis, processing, and reporting.
Yes, both the single-record and full-dataset APIs are JSON-based for compatibility. To access them externally from pipelines, processes, applications, Web forms, or anything else, simply open the port using AWS that the two APIs are running on, and they can be accessed from anywhere. You can change/configure the ports of access as well if you prefer.
Other than theoretical limits of physics and infinity, there are none. Have at it. You can use more powerful EC2 instances for massive data requirements if necessary as well.
Other than reading data from your databases/files and writing out results, all processing occurs in-memory. In other words, it is lightning-fast. Using more advanced AWS hardware infrastructure and more powerful EC2 machines can be leveraged to increase performance as well if desired.
Yes. We want you to be successful and will help you if you need it.
Start using Interzoid's AI-Powered Data Matching on AWS EC2 today and experience the power of AI-driven data matching.
Get Started with Interzoid on AWS Marketplace